Scaling Law之下,MoE(混合專家)如今已經(jīng)成為各大模型廠商擴(kuò)展模型能力的制勝法寶。
不過,在高效實(shí)現(xiàn)模型參數(shù)規(guī)模化的同時(shí),MoE的訓(xùn)練難題也日益凸顯:
訓(xùn)練效率不足,甚至一半以上訓(xùn)練時(shí)間都浪費(fèi)在“等待”上。

現(xiàn)在,為了突破MoE的訓(xùn)練瓶頸,華為出手了:
構(gòu)建了一套名為Adaptive Pipe & EDPB的優(yōu)化方案,開啟“上帝視角”,讓MoE面臨“交通擁堵”的訓(xùn)練集群,實(shí)現(xiàn)無等待流暢運(yùn)行。
MoE大規(guī)模訓(xùn)練難題:一半以上的訓(xùn)練時(shí)間在等待?
實(shí)踐已經(jīng)表明,MoE模型訓(xùn)練集群的效率面臨兩方面挑戰(zhàn):
首先,是專家并行引入了計(jì)算和通信等待。
當(dāng)模型規(guī)模較大時(shí),需要切分專家到不同設(shè)備形成并行(EP),這就引入額外All-to-All通信。
與此同時(shí),MoE層絕大部分EP通信與計(jì)算存在時(shí)序依賴關(guān)系,一般的串行執(zhí)行模式會(huì)導(dǎo)致大量計(jì)算單元空閑,等待通信。

其次,負(fù)載不均會(huì)引入計(jì)算和計(jì)算等待。
MoE算法核心是“有能者居之”,在訓(xùn)練過程中會(huì)出現(xiàn)部分熱專家被頻繁調(diào)用,而冷專家使用率較低的情況。
同時(shí),真實(shí)訓(xùn)練數(shù)據(jù)的長(zhǎng)度不一,不同的模型層(如稀疏層、嵌入層等)的計(jì)算量也存在明顯差異,造成不同卡之間計(jì)算也在互相等待。
用一個(gè)形象點(diǎn)的說法就是,MoE訓(xùn)練系統(tǒng)就像一個(gè)存在局部交通阻塞的城區(qū),面臨兩大核心問題:
-人車混行阻塞:所有車輛(計(jì)算)與行人(通信)在紅綠燈交替通行,互相等待。
-車道分配僵化:固定劃分的直行、左轉(zhuǎn)車道就像靜態(tài)的專家分配,導(dǎo)致熱門車道(熱專家)大排長(zhǎng)龍,而冷門車道(冷專家)閑置。
針對(duì)以上問題,華為團(tuán)隊(duì)打造了“智慧化交通”設(shè)施:
首先,建造“行人地下通道”(通信掩蓋技術(shù)),徹底分離人車動(dòng)線,使計(jì)算不再等待通信。
其次,部署“智能可變車道”(動(dòng)態(tài)專家路由),根據(jù)實(shí)時(shí)車流(數(shù)據(jù)分布)動(dòng)態(tài)調(diào)整車道功能,讓閑置的左轉(zhuǎn)車道也能分擔(dān)直行壓力,實(shí)現(xiàn)負(fù)載均衡。
這套組合方案既解決了資源分配不均的問題,又消除了通信阻塞的瓶頸,就像為城市交通裝上了“智慧大腦”,讓每個(gè)方向的通行效率都得到最大化提升。
DeployMind仿真平臺(tái),小時(shí)級(jí)自動(dòng)并行尋優(yōu)
具體來說,華為首先構(gòu)建了名為DeployMind的仿真平臺(tái),它是一個(gè)基于昇騰硬件訓(xùn)練系統(tǒng)的“數(shù)字孿生”平臺(tái),通過計(jì)算/通信/內(nèi)存三維度的多層級(jí)建模、昇騰硬件系統(tǒng)的高精度映射、全局化算法加速運(yùn)行等技術(shù),能在1小時(shí)內(nèi)模擬百萬次訓(xùn)練場(chǎng)景,實(shí)現(xiàn)MoE模型多樣化訓(xùn)練負(fù)載的快速分析和自動(dòng)找到與集群硬件規(guī)格匹配的最優(yōu)策略選擇。
在訓(xùn)練實(shí)踐驗(yàn)證中,該建模框架可達(dá)到90%精度指標(biāo),實(shí)現(xiàn)低成本且高效的最優(yōu)并行選擇。
針對(duì)Pangu Ultra MoE 718B模型,在單卡內(nèi)存使用約束下,華為通過DeployMind以訓(xùn)練性能為目標(biāo)找到了TP8/PP16/VPP2/EP32(其中TP只作用于Attention),這一最適合昇騰集群硬件規(guī)格的并行方案,綜合實(shí)現(xiàn)計(jì)算、通信、內(nèi)存的最佳平衡。
通信掩蓋>98%,讓計(jì)算不再等待通信
華為還提出了一套名為Adaptive Pipe的通信掩蓋框架。在DeployMind仿真平臺(tái)自動(dòng)求解最優(yōu)并行的基礎(chǔ)上,采用層次化All-to-All降低機(jī)間通信和自適應(yīng)細(xì)粒度前反向掩蓋,實(shí)現(xiàn)通信幾乎“零暴露”。
層次化專家并行通信
針對(duì)不同服務(wù)器之間通信帶寬低,但機(jī)內(nèi)通信帶寬高的特點(diǎn),華為創(chuàng)新地將通信過程拆成了兩步走:
第一步,讓各個(gè)機(jī)器上“位置相同”的計(jì)算單元聯(lián)手,快速地從所有機(jī)器上收集完整的數(shù)據(jù)塊(Token);
第二步,每臺(tái)機(jī)器內(nèi)部先對(duì)數(shù)據(jù)塊進(jìn)行整理,然后利用機(jī)器內(nèi)部的高速通道,快速完成互相交換。
這種分層設(shè)計(jì)的巧妙之處在于,它把每個(gè)數(shù)據(jù)塊最多的復(fù)制分發(fā)操作都限制在單臺(tái)機(jī)器內(nèi)部的高速網(wǎng)絡(luò)上完成,而在跨機(jī)器傳輸時(shí),每個(gè)數(shù)據(jù)塊只需要發(fā)送一份拷貝,相比傳統(tǒng)All-to-All通信加速1倍。
也就是說,有效通過減少跨機(jī)通信,提升了集群的通信速度。
自適應(yīng)細(xì)粒度前反向掩蓋
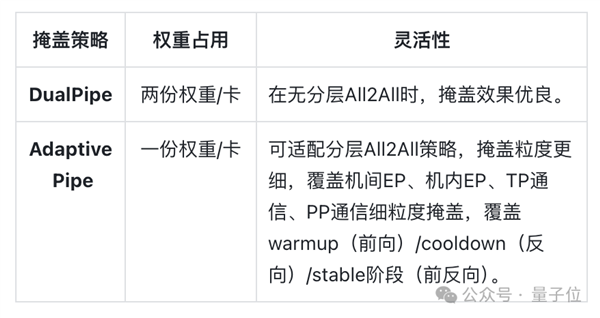
在DualPipe掩蓋框架的基礎(chǔ)上,華為基于虛擬流水線并行技術(shù),實(shí)現(xiàn)了更精密的調(diào)度,即Adaptive Pipe。
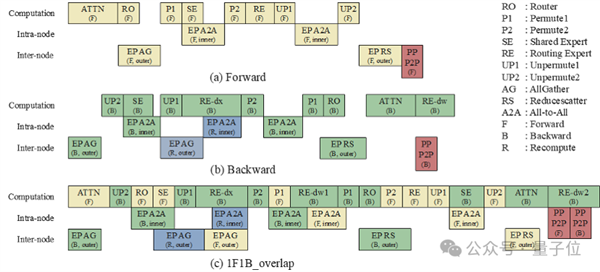
相比DualPipe,Adaptive Pipe僅利用一份權(quán)重,不僅將流水線并行所需的內(nèi)存占用減半,有效降低了計(jì)算“空泡”,釋放了流水線的峰值性能潛力;同時(shí),該策略能夠額外實(shí)現(xiàn)與分層通信的完美協(xié)同,無縫覆蓋機(jī)間與機(jī)內(nèi)兩層通信的掩蓋。
在這種層次化通信和細(xì)粒度計(jì)算通信切分調(diào)度優(yōu)化下,Adaptive Pipe可實(shí)現(xiàn)98%以上的EP通信掩蓋,讓計(jì)算引擎不受通信等待的束縛。
克服負(fù)載不均,訓(xùn)練再加速25%
由于MoE模型訓(xùn)練過程中天然存在的負(fù)載不均問題,集群訓(xùn)練效率時(shí)高時(shí)低,華為團(tuán)隊(duì)還提出了EDPB全局負(fù)載均衡,實(shí)現(xiàn)專家均衡調(diào)度。
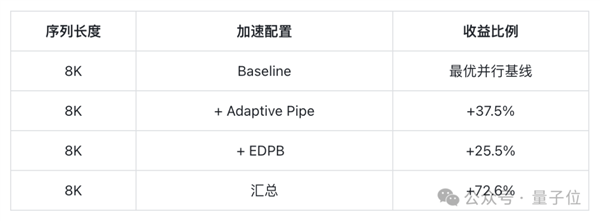
在最優(yōu)并行和通信掩蓋基礎(chǔ)上,EDPB再取得了25.5%的吞吐提升收益。
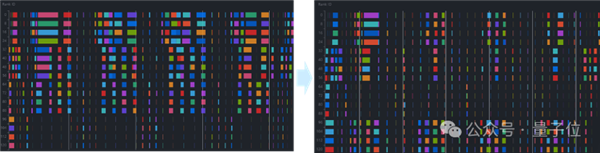
△集群P2P通信分析對(duì)比
所謂EDPB,E是專家預(yù)測(cè)動(dòng)態(tài)遷移。
MoE模型訓(xùn)練中,設(shè)備間的專家負(fù)載不均衡如同“蹺蹺板”——部分設(shè)備滿載運(yùn)行,另一些卻處于“半休眠”狀態(tài)。團(tuán)隊(duì)提出了基于多目標(biāo)優(yōu)化的專家動(dòng)態(tài)遷移技術(shù),讓專家在分布式設(shè)備間“智能流動(dòng)”。
該技術(shù)主要有三個(gè)特點(diǎn):
-預(yù)測(cè)先行,讓專家負(fù)載“看得見未來”:預(yù)測(cè)負(fù)載趨勢(shì),實(shí)現(xiàn)“計(jì)算零存儲(chǔ)開銷,預(yù)測(cè)毫秒級(jí)響應(yīng)”;
-雙層優(yōu)化,計(jì)算與通信的黃金分割點(diǎn):提出節(jié)點(diǎn)-設(shè)備雙層貪心優(yōu)化架構(gòu),在讓計(jì)算資源“齊步走”的同時(shí),給通信鏈路“減負(fù)”;
-智能觸發(fā),給專家遷移裝上“紅綠燈”:設(shè)計(jì)分層遷移閾值機(jī)制,通過預(yù)評(píng)估遷移收益動(dòng)態(tài)決策,實(shí)現(xiàn)專家遷移的智能觸發(fā)。
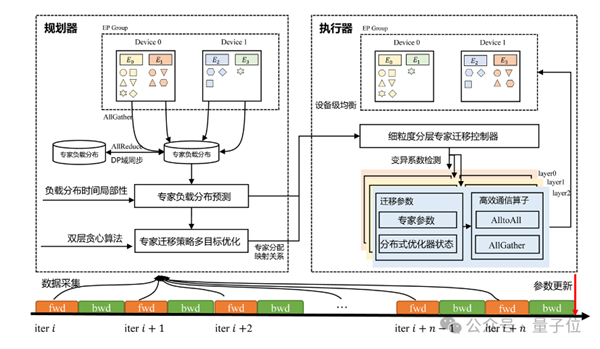
△基于專家動(dòng)態(tài)遷移的EP間負(fù)載均衡整體框架圖
D是數(shù)據(jù)重排Attention計(jì)算均衡。
在模型預(yù)訓(xùn)練中普遍采用數(shù)據(jù)拼接固定長(zhǎng)度的策略,但跨數(shù)據(jù)的稀疏Attention計(jì)算量差異顯著,會(huì)引入負(fù)載不均衡問題,導(dǎo)致DP間出現(xiàn)“快等慢”的資源浪費(fèi)。
為解決這一問題,華為團(tuán)隊(duì)提出了一種精度無損的動(dòng)態(tài)數(shù)據(jù)重排方案,其核心在于:通過線性模型量化單樣本計(jì)算耗時(shí),在嚴(yán)格保持訓(xùn)練精度無損下,批次內(nèi)采用貪心算法構(gòu)建最小化耗時(shí)的數(shù)據(jù)重排,實(shí)現(xiàn)負(fù)載均衡。
P是虛擬流水線層間負(fù)載均衡。
MoE模型通常采用混合結(jié)構(gòu),Dense層、MTP層、輸出層所在的Stage與純MoE層所在的Stage負(fù)載不均,會(huì)造成的Stage間等待。
華為團(tuán)隊(duì)提出虛擬流水線層間負(fù)載均衡技術(shù),將MTP層與輸出層分離,同時(shí)將MTP Layer的 Embedding計(jì)算前移至首個(gè)Stage,有效規(guī)避Stage間等待問題,實(shí)現(xiàn)負(fù)載均衡。
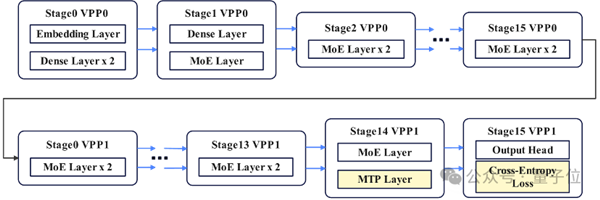
△基于異構(gòu)模塊設(shè)計(jì)的VPP并行負(fù)載均衡
系統(tǒng)端到端72.6%訓(xùn)練吞吐提升
在Pangu Ultra MoE 718B模型的訓(xùn)練實(shí)踐中,華為團(tuán)隊(duì)在8K序列上測(cè)試了Adaptive Pipe & EDPB吞吐收益情況。
實(shí)驗(yàn)結(jié)果顯示,在最優(yōu)并行策略的初始性能基礎(chǔ)上,華為這套“通信掩蓋 動(dòng)態(tài)專家遷移”的優(yōu)化方案,能實(shí)現(xiàn)系統(tǒng)端到端72.6%的訓(xùn)練吞吐提升。
總而言之,華為的這套打法可以說是為大模型訓(xùn)練優(yōu)化提供了關(guān)鍵路徑。感興趣的小伙伴可以再通過完整技術(shù)報(bào)告深入了解——
技術(shù)報(bào)告地址:https://gitcode.com/ascend-tribe/ascend-training-system/tree/main/DistributedOptimization
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。



