本站6月13日美國圣何塞現場報道——
AMD今天正式發布了新一代AI加速卡Instinct MI350系列,硬件能力再次取得飛躍,進一步強化了面對NVIDIA的競爭力。
但是我們知道,硬件性能和技術要想完全釋放潛力,尤其是在AI加速系統中,強大的軟件開發平臺是必不可少的。NVIDIA能在AI行業有如今的地位,最大的功臣和護城河就是CUDA。

AMD也有自己的一套ROCm開發平臺,一直和NVIDIA CUDA都存在一定的差距,好在最近的進步幅度也是非常喜人的,包括對眾多AI大模型、框架的即時支持,全方位的開源。
現在,我們又迎來了全新的ROCm 7版本,在最新模型與算法支持、高級AI特性、新硬件支持、集群管理、企業級特性等各方面,都再次有了長足的進步。

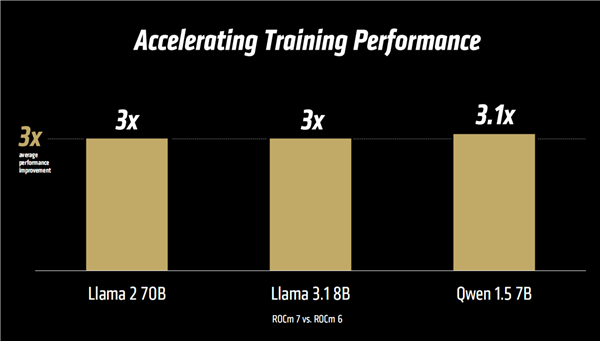
訓練方面,ROCm 7支持一系列新特性,包括多個AMD開源模型、增強的AI框架、增強的內核與算法、新的數據類型(BF16/FP8)等等。
官方聲稱對比ROCm 6,實測在Llama 2/3.1、千問1.5等多個模型中,性能提升普遍達到了3倍乃至更高。

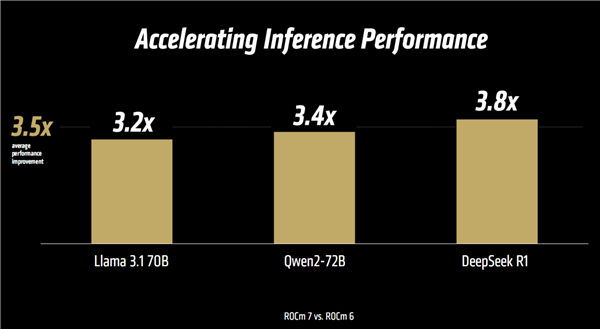
推理方面,新的變化同樣不少,包括增強框架、Serving優化、內核與算法改進、高級數據類型(FP8/FP6/FP4/混合)等。
性能提升同樣喜人,Llama 3.1、千問2、DeepSeek R1等模型實測平均達3.5倍,最高更是可達3.8倍。
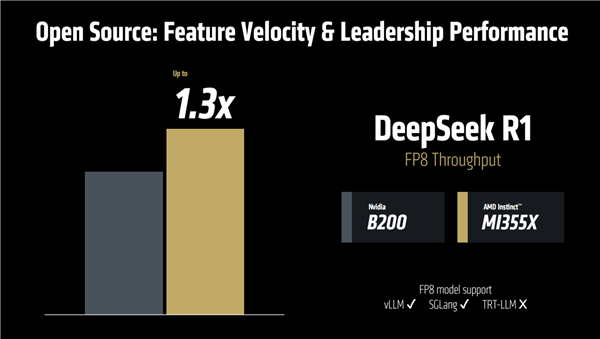
有了ROCm 7的加持,MI355X面對NVIDIA B200也是絲毫不弱,比如DeepSeek R1 FP8吞吐量可以領先達30%。
當然這只是一個例子,AMD并未更多地對比自家新品和友商競品。

除了數據中心、企業端,ROCm 7在消費端也有全面改進,新增原生支持Red Hat EPEL、Ubuntu、OpenSUSE等更多的Linux系統發行版,其中前兩者下半年實現。
Windows平臺上,也新增支持PyTorch、ONNX-EP兩大框架,分別在三季度和7月份開放預覽。

AMD還順帶介紹了下全線的消費級AI解決方案,比如移動端的銳龍AI 300系列最高可以本地端側運行240億參數大模型,銳龍AI Max 300系列更是能跑到700億參數,而新一代線程撕裂者處理器、Radeon AI顯卡組合最高可以搞定1280億參數。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



